The rise of AI-based code editors is reshaping the approach towards the software development process. Among all the AI power code-generating tools, Cursor and Windsurf have emerged as the prominent solutions. Despite offering high productivity and speed in the SLDC, there is still uncertainty in the security and quality of AI-generated code.
Benchmarking AI-generated code of Cursor and Windsurf against secure coding standards can be one of the answers. This article highlights a comparative analysis of the AI-generated code of Cursor and Windsurf with OWASP and SANS standards.
The Emergence of Cursor and Windsurf
Cursor and Windsurf serve as advanced AI editors that have revolutionized AI-assisted coding workflow with their capability. While Cursor serves as an AI-based code editor, Windsurf acts as an agentic AI code editor.
Cursor is based on VS Code and utilizes LLMs to help developers with coding solutions as they work on software development processes. It assists developers with AI-generated code, debugging, and refactoring, all while leveraging project context.
It enables developers to generate contextual AI code from simple natural language prompts. Auto debugging is another core capability that made Cursor a widely popular tool. When it is about generating design-related feedback or making changes in the codebase, this AI code editor is also useful.
On the other hand, Windsurf takes a different approach to AI code generation. It understands the context of the whole project to generate and suggest contextual AI code. The primary goal is to provide accurate and optimized code suggestions, ultimately improving overall code quality.
The most highlighting feature of Windsurf is its capability to automate various tasks in software development environments. It is more suited to working with complex codebases and large projects. This AI code editor also provides developers with features like inline code AI, local code indexing, and web searching.
The primary aim of both Cursor and Windsurf is to provide an intelligent and streamlined coding experience to developers. However, they utilize various LLMs that are based on different open-source code repositories. This introduces numerous insecure coding patterns that when embedded in the codebase lead to vulnerability. Benchmarking AI-generated code against SANS and OWASP can help developers achieve secured codebase.
Security Standards: OWASP and SANS
To ensure a secure coding standard, AI-generated code needs to be benchmarked against OWASP and SANS. Both these standards highlight the list of top crucial software vulnerabilities that developers and security teams must know.
OWASP Top 10 Vulnerabilities

Open Web Application Security Project is a non-profit organization that provides an OWASP top 10 report to highlight the 10 most critical security threats. It acts as a standard that organizations can utilize for comparing all the AI-generated codes. It will help ensure AI code from Cursor and Windsurf are free from vulnerabilities. The current 2021 OWASP top 10 list includes:
- AO1: Broken Access Control: It is a widely occurring security issue that arises due to insufficient access control. It allows malicious actors to get past authorization to access applications and sensitive data.
- A02: Cryptographic Failure: This vulnerability occurs in applications when organizations fail to implement proper encryption. As a result, threat actors can unauthorized access to the data and utilize them.
- A03: Injection: When malicious data is passed to a code interpreter in the form of a command or query, it leads to injection. This vulnerable category has been linked with 33 Common Weakness Enumerations.
- A04: Insecure Design: This category highlights numerous weaknesses or design flaws present in the architecture of an application. It also indicates the vulnerable security controls present in the architecture.
- A05: Security Misconfiguration: Security misconfiguration is widely common in applications and according to OWASP’s research 90% of applications carry misconfigurations. It highlights poorly configured security configurations in applications and frameworks.
- A06: Vulnerable and Outdated Component: This category highlights the use of components like libraries and frameworks during the application development. These components often carry known vulnerabilities that serve as threat vectors.
- A07: Identification and Authentication Failures: Ineffectiveness in managing user identity or vulnerability in the authentication system. Attackers can exploit the vulnerability to gain access to the application.
- A08: Software and Data Integrity Failure: This category highlights the usage of data from untrusted sources without integrity check and validation. This results in various exploitations and often serious cyber attacks.
- A09: Security Logging and Monitoring Failures: Many applications often lack proactive functionality and tools for logging and monitoring. This not only reduces the security visibility but also impacts the process of incident detection and response.
- A10: Server-Side Request Forgery: This category highlights the situation where an attacker sends a URL request and the application fetches the resource without validating the request. Even if the resource is protected, the attacker can get access to the data.
Along with OWASP top 10, organizations must also consider OWASP ASVS and secure coding practice checklist during comparison. The OWASP ASVS provides the necessary checklist of verification and security requirements for thorough AI code comparison. The securing coding practice checklist provides the guidelines that developers need to follow to prevent the occurrence of known vulnerabilities.
SANS Top 25 Vulnerabilities

Like OWASP’s top 10, SANS top 25 also serves as a pivotal report that showcases serious vulnerabilities within an application. The report is created by the reputed SANS institute in collaboration with CWE.
It provides a broader list of critical software vulnerabilities that organizations should mitigate. Some of the categories overalls with OWASP but it provides a distinctive perspective. All these vulnerabilities are segregated into three primary categories for simpler understanding:
- Vulnerable Communication Among Components: This category highlights the vulnerabilities that arise due to insecure interaction between software components. It highlights security flaws like authentication errors, poor input validation, and improper session management that arise due to insecure data validation.
- Insecure Security Architectures: Software often carries various weaknesses or loopholes in its security architecture. Improper access control and cryptographic implementation are major weaknesses that attackers can take advantage of.
- Poor Resource Management: This category highlights all the security flaws associated with resource management of the software. These resources are mostly sensitive data, memory, network, servers, and files.
Process To Compare Output of Cursor and Windsurf Against SANS and OWASP
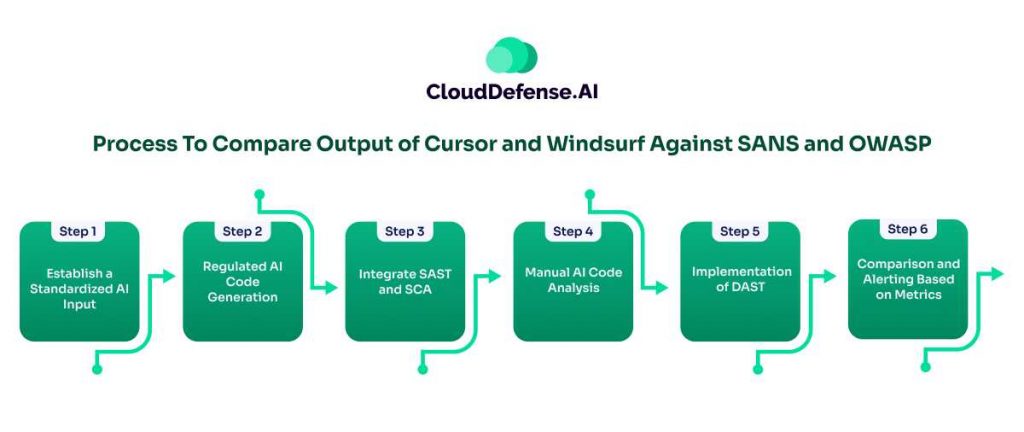
To ensure secure coding AI output from Cursor and Windsurf, comparison against OWASP and SANS standards has become a necessity. However, a detailed study on the comparison of AI code against standards like OWASP is still at the nasal stage. Organizations can utilize the following multi-step process for the comparison:
- Step 1: Establish a Standardized AI Input: Security teams along with developers should work on creating standardized prompts for Cursor and Windsurf. These prompts should address those functionalities where common vulnerabilities occur. The standardized prompts must cover API endpoint creations, user authentication, cryptography, data input, and database interactions.
- Step 2: Regulated AI Code Generation: Developers for specific functions and sections in the codebase should utilize the same prompts in both Windsurf and Cursor. While writing prompts, developers must specify the framework they are targeting. This will allow developers to regulate the AI code output of Windsurf and Cursor and ensure secure code generation.
- Step 3: Integrate SAST and SCA: Organization should implement Statistic Application Security Testing and Software Composition Analysis in the development environment. SAST and SCA will help in scanning the code for known vulnerabilities and vulnerable dependencies associated with the AI code from Windsurf and Cursor. These tools must be configured with policies and rules where the tools will constantly check the AI outputs against OWASP’s top 10 and SANS’ top 25 reports. The security team must regularly assess the SAST and SCA reports to identify specific vulnerability occurrences and their impact.
- Step 4: Manual AI Code Analysis: Security teams along with developers must work on the AI-generated code from Cursor and Windsurf. Manual AI code analysis is useful as it will help in identifying insecure design patterns and business flaws that security tools won’t detect. The teams must look for AI code that violates SANS and OWASP secure coding policies.
- Step 5: Implementation of DAST: Dynamic Application Security Testing tool must be implemented for assessing the AI-generated code that is already used in the deployed stage. If the AI code from Cursor and Windsurf has introduced vulnerabilities like XSS, flawed configuration, or SSRF, DAST will help in identifying them. This tool must also work in conjunction with OWASP and SANS reports so that it can compare the AI code against the list.
- Step 6: Comparison and Alerting Based on Metrics: The organization to tally Windsurf and Cursor AI code with OWASP and SANS standard, must perform metric-based differentiation. Teams through logs and reports must calculate the vulnerability density per KLOC. Based on the severity of security threats, the vulnerability must be categorized. Teams should also tally the occurrence of impactful vulnerabilities with respect to OWASP’s top 10 and SANS’ top 25 reports. Security must manually check whether the codebase is compliant with OWASP ASVS and SAN requirements.
Need for DevSecOps and Human Supervision
Along with tools, DevSecOps, and human expertise are also essential for benchmarking AI-generated code against SANS and OWASP standards. Organizations must conduct training for developers on secure coding practices and benchmarking against specific standards.
Even after assessment by tools, all the AI-generated codes must be thoroughly reviewed by DevSecOps teams. SAST, DAST, and SCA tools should be also integrated into the CI/CD pipeline so that AI code is constantly checked against OWASP and SANS standards.
Final Words
In today’s time, organizations are relying heavily on Cursor and Windsurf to generate AI code for the application development process. However, these AI code-generating tools don’t inherently offer secure-first AI code. A system comparison of the AI code against OWASP and SANS standards is essential for every organization. It will help in uncovering all the critical vulnerabilities present in the codebase and ensure secure coding practice.
While the research on comparative analysis of AI code is still in the nasal stage, organizations can utilize the above process for comparison. For this comparative analysis, both human expertise and tools are necessary as security tools can’t do it all. Organizations shouldn’t wait for the next vulnerability to appear in their application. They should start comparing the AI code from Cursor and Windsurf and ensure a secure coding practice.








