Considering the recent surge of modern cloud-native applications, there is an increasing need for data storage solutions that are not only high-performance but also highly scalable and resilient.
Redis, an open-source, lightning-fast, and in-memory data structure store, is the perfect solution to address these requirements. In fact, when paired with Kubernetes, the container orchestration platform of choice, Redis becomes an even more powerful tool in your arsenal.
This comprehensive blog is your guide to effortlessly setting up the Redis cluster on the Kubernetes environment. We’ll explore the key aspects of Redis and Kubernetes, walking you through the process of creating a Redis cluster in your Kubernetes setup, fine-tuning it to achieve peak performance, and effectively tackling common challenges along the way.
What is a Redis cluster?
A Redis cluster is a distributed, high-performance, and fault-tolerant database system built on the Redis in-memory data store. It’s designed to improve the scalability and availability of Redis for mission-critical applications. Redis clusters split data into multiple shards and distribute them across multiple nodes, allowing data to be horizontally scaled while maintaining low-latency access.
Such setup also provides automatic failover mechanisms, ensuring data availability even if some nodes go down. Redis clusters are an excellent choice for applications requiring fast data retrieval and high throughput, such as caching, real-time analytics, and messaging systems.
What is Kubernetes?
Kubernetes stands as an open-source container orchestration system crafted to streamline the process of deploying, scaling, and overseeing container-based applications. Originally crafted by Google and subsequently contributed to the Cloud Native Computing Foundation (CNCF), Kubernetes has emerged as the benchmark for governing and harmonizing containerized workloads across cloud-based and on-site settings.
Kubernetes offers a multitude of key functions, like automated load distribution, dynamic scaling, progressive upgrades, autonomous error recovery, and the great allocation of resources. It operates by abstracting the underlying infrastructure, effectively freeing up developers and operators from the constraints of particular hardware or cloud service providers. This, in turn, facilitates the hassle-free management of applications.
How do Redis clusters work on Kubernetes?
Redis clusters on Kubernetes function through the synergy of Redis’s inherent clustering capabilities and Kubernetes’ container orchestration features. In this setup, Kubernetes orchestrates a collection of Redis containers or pods, collectively shaping the Redis cluster.
Within this cluster, each Redis pod acts as a distinct Redis node. These nodes are categorized into master and replica nodes, guaranteeing data redundancy and robust availability.
Kubernetes takes charge of deploying, scaling, and monitoring the Redis pods, simplifying the management of the cluster’s underlying infrastructure. In contrast, Redis’s native cluster mode handles the intricate tasks of data sharding, distribution, and automated failover in the event of node failures.
The outcome is a distributed, scalable, and resilient Redis cluster where data is distributed across numerous nodes. Kubernetes diligently ensures the health and equitable distribution of Redis pods, while Redis clustering guarantees that data remains accessible with exceptional availability and performance. This makes it a well-suited solution for data-intensive applications in Kubernetes environments.
Benefits of Deploying Redis on Kubernetes

Scalability: Kubernetes simplifies the task of adjusting your Redis deployment’s scale to match shifting workloads. You have the flexibility to dynamically modify the quantity of Redis pods in response to demand.
Enhanced Availability: Kubernetes excels in ensuring high availability, automatically replacing any failed Redis pods and distributing them across various nodes. This results in reduced downtime and minimizes data loss.
Resource Optimization: Kubernetes optimizes resource utilization by efficiently distributing Redis pods throughout the cluster, making optimal use of available hardware resources.
Streamlined Deployment: Kubernetes streamlines the deployment process with automated provisioning, greatly facilitating the setup and management of Redis clusters.
Load Balancing: Kubernetes offers robust load balancing, guaranteeing an even distribution of traffic to Redis pods, thus enhancing performance and responsiveness.
Data Resilience: Combining Redis clustering with Kubernetes establishes data redundancy and failover mechanisms that safeguard your data against unforeseen failures.
Uniform Environment: Across development, testing, and production, Kubernetes ensures a consistent environment for Redis, thus promoting seamless transitions and minimizing configuration complications.
Setting up a Redis cluster on Kubernetes
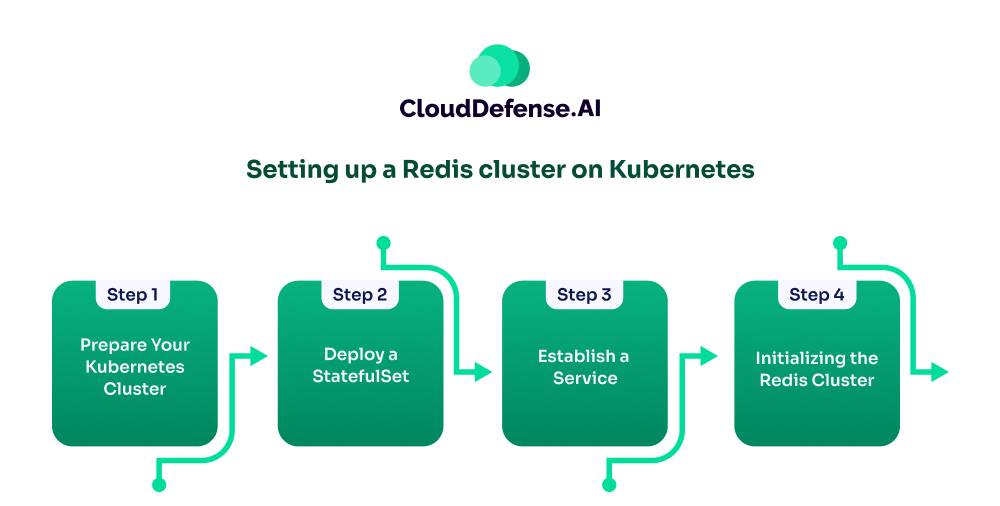
Step 1: Prepare Your Kubernetes Cluster
Before getting started with setting up a Redis cluster on Kubernetes, it’s essential to ensure that you have a functioning Kubernetes cluster in place. To establish a Kubernetes cluster, you’ll need to set up and configure the required infrastructure, which typically includes a control plane and worker nodes.
Also, ensure you have the Kubernetes command-line tool (kubectl) installed and correctly configured to interact with your cluster. This initial step sets the stage for the subsequent deployment of a Redis cluster within your Kubernetes environment.
Step 2: Deploy a StatefulSet
In the next phase, the creation of a StatefulSet becomes essential. A Kubernetes StatefulSets is a fundamental component within the Kubernetes environment that facilitates the deployment of Pods, each endowed with unique identifiers—a feature not typically available in standard Kubernetes deployments.
For databases and data stores like Redis, these unique identifiers are crucial, as they enable persistent associations between Pods and their respective data stores. Even in the event of Pod failures or node migrations, the StatefulSet ensures continued connectivity to the correct data source.
To configure the StatefulSet for your Redis cluster, specify the number of replicas required for the Pods and the container image to employ.
This command connects you to the first Redis Pod (my-redis-cluster-0) in the “my-redis-namespace” and initiates the Redis cluster configuration. The “–cluster-replicas 1” flag designates the number of replicas per master node, and “${REDIS_NODES}” includes the list of IP addresses and ports for all the Redis nodes you collected earlier.
Ultimately, by executing these commands, you’ll create and configure your Redis cluster within the Kubernetes environment, making it ready for use.
Optimizing Redis Performance on Kubernetes
Right after setting up the Redis cluster, it is crucial to optimize its performance within the Kubernetes environment. This optimization is essential to guarantee the efficient operation of your Redis cluster, enabling it to effectively manage the demands of your applications.
To achieve this, consider the following key best practices and strategies for enhancing Redis performance on Kubernetes:
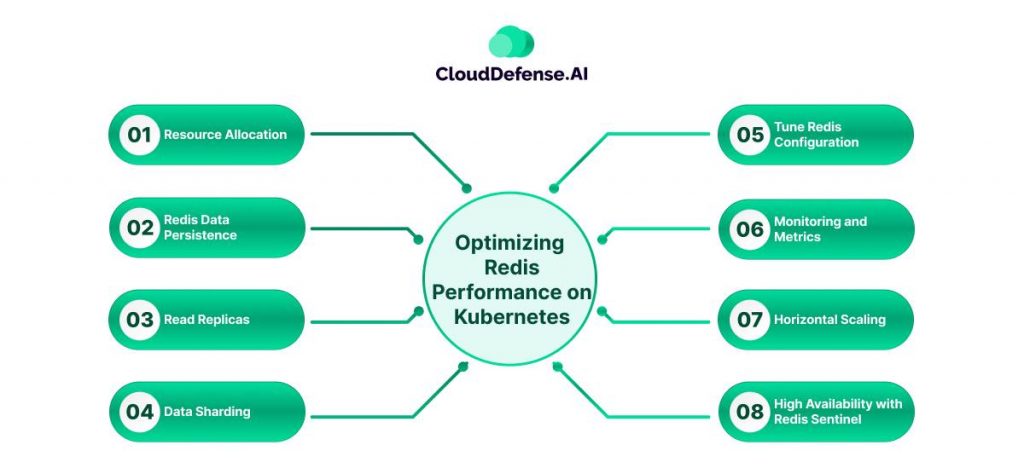
- Resource Allocation: Properly allocate CPU and memory resources for each Redis Pod within your StatefulSet configuration to prevent resource contention and improve performance.
- Redis Data Persistence: Configure Redis for data persistence using mechanisms like RDB snapshots and AOF logs to prevent data loss in case of Pod restarts. Be mindful of the balance between persistence and performance.
- Read Replicas: Implement read replicas to distribute read traffic efficiently, reducing the load on the primary Redis node and enhancing read performance.
- Data Sharding: For large datasets, consider sharding data across multiple Redis instances to improve both read and write performance.
- Tune Redis Configuration: Adjust Redis configuration parameters, such as maxmemory, maxclients, and timeout, to align with the specific requirements of your use case.
- Monitoring and Metrics: Set up robust monitoring and alerting using tools like Prometheus and Grafana to track essential metrics like memory usage, connections, and command latency.
- Horizontal Scaling: Be prepared to scale your Redis cluster horizontally by adding more Redis nodes or shards as your application’s demand increases.
- High Availability with Redis Sentinel: Implement Redis Sentinel to ensure high availability by enabling automatic Redis cluster failover in the event of primary node failures.
Monitoring and Troubleshooting Redis on Kubernetes
Monitoring and troubleshooting Redis on Kubernetes is essential to ensuring the reliability and performance of your Redis cluster. Below are some Redis security best practices for monitoring and troubleshooting in a Kubernetes environment:
Redis Monitoring in Kubernetes:
Use Prometheus and Grafana: Implement Prometheus for metric collection and Grafana for visualization. Kubernetes provides native integrations for these tools. You can use the prometheus-operator helm chart to deploy them easily. Configure Prometheus to scrape Redis metrics, such as memory usage, connections, and command latency.
Redis Exporter: Deploy a Redis Exporter, a third-party tool that collects Redis-specific metrics and exposes them in a format compatible with Prometheus. This allows you to monitor Redis more comprehensively.
Custom Metrics: Create custom metrics and alerts based on your application’s specific requirements. For example, you might want to monitor the number of keys in Redis or specific cache hit rates.
Alerting: Set up alerting rules in Prometheus to receive notifications when Redis metrics breach predefined thresholds. Alerts can be sent via various channels, such as email, Slack, or PagerDuty.
Service Discovery: Use Kubernetes service discovery to dynamically discover Redis instances, which simplifies configuration and maintenance as the Redis cluster scales.
Troubleshooting in Kubernetes:
Logs and Events: Inspect the logs of your Redis Pods to identify issues. Use kubectl logs to view container logs. Additionally, check Kubernetes events to see if there are any Pod scheduling or deployment problems.
Redis-CLI: Use redis-cli to connect to your Redis Pods directly. This tool is invaluable for diagnosing Redis-related issues and performing manual checks on your Redis cluster’s health.
Pod Inspection: If you suspect issues with a specific Pod, you can use kubectl exec to enter the Pod and run diagnostics commands or examine the configuration files.
Scaling and Redeployment: If you’re facing performance issues, consider scaling your Redis cluster horizontally by adding more Redis nodes or read replicas. Additionally, you can perform rolling updates to upgrade Redis versions or apply configuration changes.
Data Integrity Checks: Regularly run data integrity checks on your Redis data. Tools like Redis-check and Redis Sentinel can help verify data consistency.
Network Troubleshooting: If there are network-related issues, check Kubernetes network policies, firewall rules, and DNS configurations. Ensure that Redis Pods can communicate with each other and with clients.
Resource Bottlenecks: Investigate resource bottlenecks, such as CPU or memory constraints, that may affect Redis performance. Adjust resource requests and limits accordingly.
Security Checks: Regularly perform security audits to identify potential vulnerabilities or misconfigurations. Ensure that Redis is adequately protected against unauthorized access.
FAQ
1. What is the purpose of the Redis cluster?
The purpose of a Redis cluster is to enhance the scalability and high availability of the Redis in-memory data store. It achieves this by distributing data across multiple nodes, enabling faster data retrieval, and accommodating larger data sets. Also, Redis clusters provide fault tolerance through automatic failover mechanisms, making them well-suited for applications requiring real-time data, caching, and rapid data processing.
2. When should I use the Redis Cluster?
You should consider using a Redis Cluster when your applications demand improved performance, scalability, and high availability. Redis Clusters are ideal for scenarios where data needs to be rapidly accessed and distributed across multiple nodes, such as in web applications, real-time analytics, messaging systems, and caching. I
3. What is the difference between Redis and Redis Cluster?
The primary distinction between Redis and Redis Cluster lies in their architecture and capabilities. Redis is a standalone, in-memory data store, while Redis Cluster is a distributed version of Redis designed for horizontal scaling and high availability. Redis operates as a single instance, whereas Redis Cluster partitions data across multiple nodes.
The choice between the two depends on your specific application requirements and scalability needs.
Final Thoughts
In summary, deploying the Redis cluster on Kubernetes is a powerful combination that harnesses the strengths of both technologies. Redis, known for its exceptional speed and capacity for in-memory data storage, effectively fulfills the demands of data-intensive applications. Meanwhile, Kubernetes offers the orchestration, scalability, and high availability necessary for contemporary cloud-native settings.
Whether you’re working with real-time analytics, caching, or any application that relies on rapid data processing, Redis on Kubernetes empowers you to meet the demands of today’s dynamic, data-driven world.








